

本套课程大数据开发工程师(微专业),构建复杂大数据分析系统,课程官方售价3800元,本次更新共分为13个部分,文件大小共计170.13G。本套课程设计以企业真实的大数据架构和案例为出发点,强调将大数据思维与实践相结合。项目实操接入网易云,提供真实的大数据开发环境,帮助全方位掌控大数据技能,文章底部附下载地址。
课程优势:
1.真实案例教学:通过一个真实的案例进行串联,让你完全了解开发过程中的数据流变化,对比传统培训不同案例用不同的数据源现状,本课程让你体验的是真实的开发流程和业务知识;
2.分布式集群教学:分布式集群的价格极其昂贵,大多数培训课程建议学员在单机搭建,但这种人为屏蔽分布式系统的优势和复杂性的做法,让学员在实际工作中对于错误定位、性能调优上的能力明显落后于其他人,为了避免此类情况,我们提供类似真实工作环境的分布式集群环境;
3.工作流程为重点教学:本课程召集了网易内部各大数据部门的核心开发人员,梳理了通用的大数据工作流程融入到教学中,学完后除了掌握基本的大数据技能外,还能掌握整套工作流程及方法,避免了在面试中的知识碎片化及无法针对场景应用对应大数据技能的现象;
4.一线的工程师教学:一线工程师在实际生产经验及大数据框架的优劣,框架存在的bug及框架未来新的特性了解上有着无可比拟的优势,通过一线工程师的教学,你可以直接了解他们遇到过的各种开发及性能调优问题,站在前人的基础上在大数据工作上走的更稳健。
大数据开发工程师 视频截图
大数据开发工程师 视频截图
课程目录.H-30187:大数据开发工程师
{10}–网易严选项目实战
{1}–电商严选数据仓库实战
#1.2#–[下载]代码下载.pdf
#1.3#–[下载资料]电商严选数据仓库实战-数据.pdf
{10}–案例实战3——订单及履约管理
[1.10.1]–1.7.1出库(妥投)累积快照.mp4
[1.10.2]–1.7.2谈谈库存周转率、售罄率?.mp4
[1.10.3]–1.7.3总结:维度建模项目经验.mp4
{4}–电商发展概况&维度建模简介
[1.4.1]–1.1.1电商发展状况及数据应用场景.mp4
[1.4.2]–1.1.2星型模式与OLAP多维数据库.mp4
[1.4.3]–1.1.3Kimball的DWBI架构.mp4
{5}–维度建模基础技术
[1.5.1]–1.2.1维度建模基础概念.mp4
[1.5.2]–1.2.2维度及事实类型.mp4
[1.5.3]–1.2.3维度建模基本过程及思想.mp4
{6}–维度建模进阶及高级技术
[1.6.1]–1.3.1维度进阶与高级设计技术.mp4
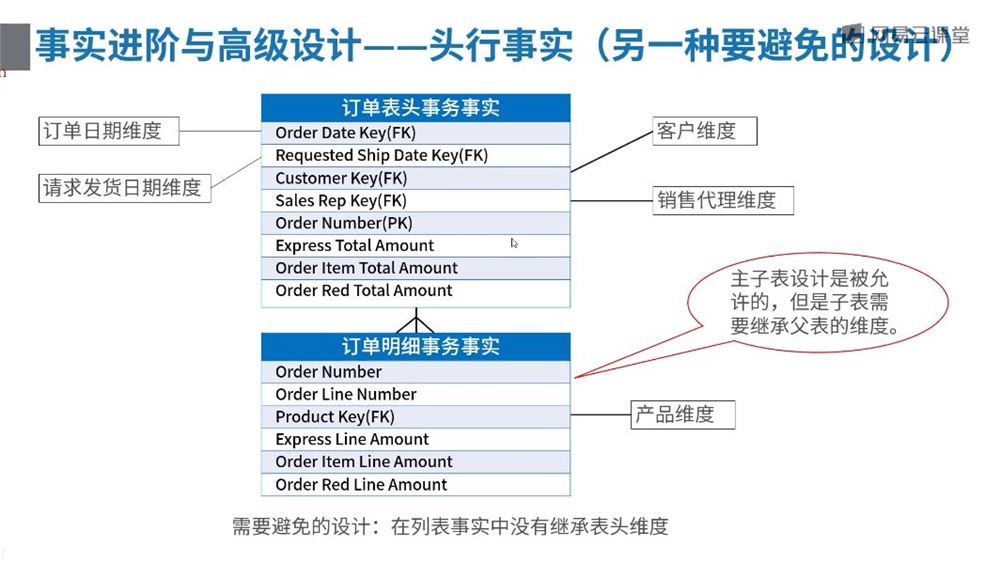
[1.6.2]–1.3.2事实进阶与高级设计技术.mp4
[1.6.3]–1.3.3避免常见的维度建模错误.mp4
{7}–数仓架构及规范
[1.7.1]–1.4.1数仓分层架构.mp4
[1.7.2]–1.4.2数仓设计规范.mp4
{8}–案例实战1——订单及库存管理
[1.8.1]–1.5.1项目背景及方案设计.mp4
[1.8.2]–1.5.2库存主题域设计.mp4
[1.8.3]–1.5.3交易主题域设计.mp4
{9}–案例实战2——订单及库存管理(主题域设计进阶)
[1.9.1]–1.6.1订单管理.mp4
[1.9.2]–1.6.2销售增长曲线.mp4
[1.9.3]–1.6.3模型开发实践.mp4
{2}–电商严选实时数仓实战
#2.2#–[下载]代码下载.pdf
{3}–实时数仓基础
[2.3.1]–2.1.1实时数仓概念.mp4
[2.3.2]–2.1.2相关技术框架.mp4
[2.3.3]–2.1.3业界实现方案.mp4
{4}–严选实时数仓
[2.4.1]–2.2.1业务背景和问题.mp4
[2.4.2]–2.2.2数据建模.mp4
[2.4.3]–2.2.3技术架构.mp4
{5}–交易域建模实战
[2.5.1]–2.3.1业务过程介绍和环境准备.mp4
[2.5.2]–2.3.2订单表设计和开发.mp4
[2.5.3]–2.3.3订单明细表设计和开发.mp4
{6}–流量域建模实战
[2.6.1]–2.4.1流量域明细表.mp4
{7}–维表实战
[2.7.1]–2.5.1商品维表开发.mp4
{8}–实时应用-数据大屏-开发
[2.8.1]–2.6.1流水相关模型开发-1.mp4
[2.8.2]–2.6.2维表关联优化.mp4
{9}–实时应用-数据大屏-流量
[2.9.1]–2.7.1uv与在线用户数.mp4
[2.9.2]–2.7.2近似计算.mp4
[2.9.3]–2.7.3数据补偿.mp4
{3}–电商严选用户画像实战
#3.2#–[下载]代码下载.pdf
{3}–用户画像基础
[3.3.1]–3.1.1什么是用户画像_01.mp4
[3.3.2]–3.1.2构建用户画像意义.mp4
[3.3.3]–3.1.3用户标签体系.mp4
{4}–用户画像建模
[3.4.1]–3.2.1用户标签建模方法.mp4
[3.4.2]–3.2.2用户画像技术架构.mp4
{5}–用户属性画像
[3.5.1]–3.3.1用户标签分类.mp4
[3.5.2]–3.3.2数据收集和清洗.mp4
[3.5.3]–3.3.3用户属性标签挖掘_1.mp4
{6}–用户行为画像
[3.6.1]–3.4.1用户行为日志数据采集和接入.mp4
[3.6.2]–3.4.2用户活跃度标签统计分析_1.mp4
{7}–用户偏好画像和群体用户画像
[3.7.1]–3.5.1用户类目兴趣.mp4
[3.7.2]–3.5.2统一用户标识.mp4
[3.7.3]–3.5.3用户人群画像.mp4
{8}–用户画像应用与总结
[3.8.1]–3.6.1用户全生命周期精准营销.mp4
[3.8.2]–3.6.2个性化推荐.mp4
[3.8.3]–3.6.3用户画像总结.mp4
{11}–网易有道项目实战
{11}–网易有道项目实战
#1#–[课前准备]有道广告项目实战数据包.pdf
{2}–网易有道广告实时数据处理实战
{2}–广告业务简介及统计系统架构
[2.2.1]–1.1.1广告业务简介及统计系统架构-广告业务简介及统计需求.pdf
[2.2.2]–1.1.1广告业务简介及统计需求.mp4
[2.2.3]–1.1.2广告业务简介及统计系统架构-新统计架构应运而生.pdf
[2.2.4]–1.1.2新统计架构应运而生.mp4
{3}–组件选型
[2.3.1]–1.2.1组件选型-数据存储选型.pdf
[2.3.2]–1.2.1数据存储选型.mp4
[2.3.3]–1.2.2组件选型-数据格式选型.pdf
[2.3.4]–1.2.2数据格式选型.mp4
[2.3.5]–1.2.3组件选型-数据再处理组件选型.pdf
[2.3.6]–1.2.3数据再处理组件选型.mp4
{4}–实时统计
#2.4.1#–[课程代码下载].pdf
[2.4.2]–1.3.1实时统计-Druid.pdf
[2.4.3]–1.3.1实时统计-Druid.mp4
[2.4.4]–1.3.2实时统计-实时统计数据注入.pdf
[2.4.5]–1.3.2实时统计数据注入-理论.mp4
[2.4.6]–1.3.2实时统计数据注入-实操.mp4
[2.4.7]–1.3.3实时统计-统计结果查询及数据看板.pdf
[2.4.8]–1.3.3统计结果查询及数据看板-理论.mp4
[2.4.9]–1.3.3统计结果查询及数据看板-实操.mp4
{3}–网易有道广告离线数据处理实战
{2}–离线统计
[3.2.1]–2.1.1-Kafka落地HDFS-理论.mp4
[3.2.2]–2.1.1-Kafka落地HDFS-实操.mp4
[3.2.3]–2.1.2批量统计.mp4
[3.2.4]–2.1.3服务高可用.mp4
{3}–系统监控
[3.3.1]–2.2.1监控系统.mp4
[3.3.2]–2.2.2集群监控.mp4
{4}–广告离线数据分析
[3.4.1]–课前准备-zeppelin安装.pdf
[3.4.2]–2.3.1广告离线数据分析-ApacheZeppelin.mp4
[3.4.3]–2.3.2广告离线数据分析-SparkonZeppelin实战.mp4
{4}–网易有道广告精准投放推荐系统
{2}–RTB广告流程
[4.2.1]–3.1.1广告实时竞价RTB.mp4
{3}–广告业务用户画像
[4.3.1]–3.2.1用户画像介绍.mp4
[4.3.2]–3.2.2使用SparkML预测用户性别.mp4
[4.3.3]–3.2.3用户画像介绍在广告业务中的应用.mp4
{4}–使用Redis构建用户画像在线库
[4.4.1]–3.3.1Redis中使用Lua脚本.mp4
[4.4.2]–3.3.2用户画像在线库需求与设计.mp4
[4.4.3]–3.3.3用户画像在线库服务端Lua脚本实现.mp4
[4.4.4]–3.3.4用户画像在线库基于Lettuce的客户端代码实现.mp4
{12}–网易游戏项目实战
{12}–网易游戏项目实战
{1}–图计算应用
{1}–课前准备
#1.1.2#–[下载]第1、2节代码下载.pdf
#1.1.3#–[下载]第3、4节代码下载.pdf
#1.1.4#–[下载]图计算实验环境.pdf
{2}–图的基本概念
[1.2.1]–1.1.1-图计算应用-图的基本概念-什么是图.mp4
[1.2.2]–1.1.2-图计算应用-图的基本概念-图的典型例子.mp4
{3}–图如何存储
[1.3.1]–1.2.1-图计算应用-图如何存储-图的数据结构表达.mp4
[1.3.2]–1.2.2.1-图数据库初识(第一部分图数据库概述).mp4
[1.3.3]–1.2.2.2-图数据库初识(第二部分neo4j入门介绍).mp4
[1.3.4]–1.2.2.3-图数据库初识(第三部分neo4j的安装和部署).mp4
[1.3.5]–1.2.2.4-图数据库初识(第四部分neo4j数据建模).mp4
[1.3.6]–1.2.2.5-图数据库初识(第五部分neo4j数据导入).mp4
[1.3.7]–1.2.3.1-图数据库进阶(第一部分).mp4
[1.3.8]–1.2.3.2-图数据库进阶(第二部分).mp4
[1.3.9]–1.2.4-图数据库高级功能.mp4
{4}–图计算概念
[1.4.1]–1.3.1-什么是图计算.mp4
[1.4.2]–1.3.2_图计算框架的发展.mp4
{5}–图深度学习
[1.5.1]–1.4.1_什么是图深度学习.mp4
[1.5.2]–1.4.2-图开源深度学习框架.mp4
[1.5.3]–1.4.3.1-图深度学习的应用1.mp4
[1.5.4]–1.4.3.2-图深度学习的应用2.mp4
{2}–实时数据处理实战
{1}–课前准备
#2.1.2#–[下载]实验环境、数据、代码下载.pdf
{2}–Flink流式处理编程-游戏日志ETL项目
[2.2.10]–2.1.5-写入文件系统(理论).mp4
[2.2.11]–2.1.5-写入文件系统(实操).mp4
[2.2.12]–2.1.6.写入Elasticsearch(实操).mp4
[2.2.13]–2.1.6.写入Elasticsearch(理论).mp4
[2.2.1]–2.1.1-本地测试Flink任务(理论).mp4
[2.2.2]–2.1.1-本地测试Flink任务(实操).mp4
[2.2.3]–2.1.1-本地测试Flink任务(实操2).mp4
[2.2.4]–2.1.2-Kafka数据源和存储(理论).mp4
[2.2.5]–2.1.2-Kafka数据源和存储(实操).mp4
[2.2.6]–2.1.3-DataStreamAPI解析日志(理论).mp4
[2.2.7]–2.1.3-DataStreamAPI解析日志(实操).mp4
[2.2.8]–2.1.4-状态管理和动态配置(理论).mp4
[2.2.9]–2.1.4-状态管理和动态配置(实操).mp4
[2.3.1]–2.2.1-Window窗口(理论).mp4
[2.3.2]–2.2.1-Window窗口(实操).mp4
[2.3.3]–2.2.2-事件时间处理乱序数据(理论).mp4
[2.3.4]–2.2.2-事件时间处理乱序数据(实操).mp4
{3}–Flink流式处理编程-实时日志监控项目
[2.3.1]–2.2.1-Window窗口(理论).mp4
[2.3.2]–2.2.1-Window窗口(实操).mp4
[2.3.3]–2.2.2-事件时间处理乱序数据(理论).mp4
[2.3.4]–2.2.2-事件时间处理乱序数据(实操).mp4
{3}–多数据源游戏业务实时分析
{1}–课前准备
#3.1.2#–[下载]实验环境.pdf
{2}–Kudu实时游戏分析
#3.2.1#–[下载]本节代码下载.pdf
[3.2.2]–3.1.1什么是Kudu.mp4
[3.2.3]–3.1.2环境安装(理论).mp4
[3.2.4]–3.1.2环境安装(实操).mp4
[3.2.5]–3.1.3日志流式写入开发(理论).mp4
[3.2.6]–3.1.3日志流式写入开发(实操).mp4
[3.2.7]–3.1.4业务分析.mp4
[3.2.8]–3.1.5优化.mp4
{3}–Presto多数据源游戏业务分析
#3.3.1#–[下载]本节代码下载.pdf
[3.3.10]–3.2.5.2_标量函数(实操).mp4
[3.3.11]–3.2.5.3_聚合函数(实操).mp4
[3.3.12]–3.2.5.4_sql类型与java类型对应(实操).mp4
[3.3.13]–3.2.5.5_函数注册(实操).mp4
[3.3.14]–3.2.6自定义连接器扩展.mp4
[3.3.2]–3.2.1什么是Presto.mp4
[3.3.3]–3.2.2.1环境准备.mp4
[3.3.4]–3.2.2.2_演示(实操).mp4
[3.3.5]–3.2.3.1Presto常用SQL(理论).mp4
[3.3.6]–3.2.3.2DDL&DML(实操).mp4
[3.3.7]–3.2.3.3查询(实操).mp4
[3.3.8]–3.2.4业务分析.mp4
[3.3.9]–3.2.5.1自定义函数扩展(理论).mp4
{4}–elasticsearch在游戏监控中的应用
#3.4.8#–[考试附件下载]elasticsearch在游戏监控中的应用.pdf
[3.4.1]–3.3.1_监控ES节点写入线程池(理论).mp4
[3.4.2]–3.3.1_监控ES节点写入线程池(实操).mp4
[3.4.3]–3.3.2_监控游戏api调用次数(理论).mp4
[3.4.4]–3.3.2_监控游戏api调用次数(实操).mp4
[3.4.5]–3.3.3_游戏关键字告警(理论).mp4
[3.4.6]–3.3.3_游戏关键字告警(实操).mp4
{13}–延伸学习
{1}–预备课
#1.2#–知识积累参考资料.pdf
#1.3#–Google3论文中文版.pdf
[1.1]–大数据直播分享.mp4
课件.txt
{2}–项目实战汇总
[2.1]–[直播0809]数据质量保障体系建设.mp4
[2.2]–[直播1030]使用FlinkSQLAPI提高开发效率.mp4
{13}–网易云音乐项目实战
{13}–网易云音乐项目实战
{1}–网易云音乐搜索业务实时特征实战
{2}–搜索业务简介和需求背景
[1.2.1]–1.1.1-前言与准备工作.mp4
[1.2.2]–1.1.2-业务背景和需求介绍.mp4
{3}–用户日志初探
#1.3.4#–[下载]日志文件链接.pdf
[1.3.1]–1.2.1-用户日志简介.mp4
[1.3.2]–1.2.2-需要处理的关键字段.mp4
[1.3.3]–1.2.3-模拟数据源的开发.mp4
{4}–日志的读取、清洗和转换
[1.4.1]–1.3.1读取用户日志.mp4
[1.4.2]–1.3.2检查日志是否符合业务需求.mp4
[1.4.3]–1.3.3提取日志中的关键信息.mp4
{5}–用户Action的关联
[1.5.1]–1.4.1-指定数据的时间类型.mp4
[1.5.2]–1.4.2-使用MapState储存数据.mp4
[1.5.3]–1.4.3-关联搜索和播放Action.mp4
[1.5.4]–1.4.4-关联其他Action.mp4
{6}–实时特征的产出
[1.6.1]–1.5.1构建自定义SinkFunction.mp4
[1.6.2]–1.5.2从业务角度解释TTL的作用.mp4
[1.6.3]–1.5.3运行、调试并查看结果.mp4
[1.6.4]–1.5.4总结和作业.mp4
{2}–网易云音乐每日推歌实战
{2}–每日推歌需求背景
[2.2.1]–2.1.1每日推歌背景介绍.mp4
[2.2.2]–2.1.2实时数据处理需求介绍.mp4
{3}–用户行为日志流预处理
[2.3.1]–2.2.1读取和消费用户行为流.mp4
[2.3.2]–2.2.2过滤获取业务数据流.mp4
{4}–实时特征的产出
[2.4.1]–2.3.1数据流根据歌曲进行聚合.mp4
[2.4.2]–2.3.2按时间聚合统计歌曲排行.mp4
{5}–特征的实时存储
[2.5.1]–2.4.1特征写出消息队列.mp4
{3}–网易云音乐推荐算法应用
{2}–云音乐用户画像体系
[3.2.1]–3.1.1用户画像定义.mp4
[3.2.2]–3.1.2用户画像意义.mp4
[3.2.3]–3.1.3云音乐用户画像体系.mp4
[3.2.4]–3.1.4云音乐用户画像应用.mp4
{3}–云音乐特征工程
[3.3.1]–3.2.1特征工程定义.mp4
[3.3.2]–3.2.2特征预处理.mp4
[3.3.3]–3.2.3特征选择.mp4
[3.3.4]–3.2.4特征降维.mp4
{4}–音乐场景召回
[3.4.1]–3.3.1推荐系统召回架构.mp4
[3.4.2]–3.3.2协同过滤(CF)算法.mp4
[3.4.3]–3.3.3基于内容(CB)召回.mp4
[3.4.4]–3.3.4深度向量召回.mp4
[3.4.5]–3.3.5前沿召回模型介绍.mp4
{5}–音乐场景排序
[3.5.1]–3.4.1云音乐推荐排序架构.mp4
[3.5.2]–3.4.2云音乐推荐离线粗排序介绍.mp4
[3.5.3]–3.4.3云音乐推荐离线精排序介绍.mp4
[3.5.4]–3.4.4云音乐推荐线上精排序介绍.mp4
{1}–零基础复习课
{1}–Java基础复习课
[1.10]–城堡游戏.mp4
[1.11]–消除代码复制.mp4
[1.12]–封装.mp4
[1.13]–可扩展性.mp4
[1.14]–框架加数据.mp4
[1.1]–媒体资料库的故事.mp4
[1.2]–继承.mp4
[1.3]–子类父类关系.mp4
[1.4]–子类父类关系II.mp4
[1.5]–多态变量.mp4
[1.6]–向上造型.mp4
[1.7]–多态.mp4
[1.8]–Object类.mp4
[1.9]–DoME的新类型.mp4
{2}–MySQL基础复习课
{10}–MySQL程序开发
#2.10.3#–MySQL字符集案例SQL.pdf
#2.10.5#–Java程序连接MySQL代码示例.pdf
#2.10.7#–DAO框架代码示例.pdf
[2.10.1]–MySQL字符集(上).mp4
[2.10.2]–MySQL字符集(下).mp4
[2.10.4]–程序连接MySQL.mp4
[2.10.6]–DAO框架的使用.mp4
{1}–初识MySQL
#2.1.3#–安装方式参考.pdf
#2.1.4#–课程使用的命令.pdf
#2.1.6#–课程用到的命令.pdf
#2.1.8#–SQL基础教程.pdf
#2.1.9#–课程SQL.pdf
[2.1.1]–认识MySQL.mp4
[2.1.2]–轻松安装MySQL.mp4
[2.1.5]–MySQL数据库连接(1).mp4
[2.1.5]–MySQL数据库连接.mp4
[2.1.7]–SQL语言入门.mp4
{2}–MySQL数据类型
#2.2.3#–课堂案例SQL.pdf
[2.2.1]–MySQL数据类型(上).mp4
[2.2.2]–MySQL数据类型(下).mp4
{3}–MySQL数据对象
#2.3.2#–MySQL数据对象教学案例SQL.pdf
[2.3.1]–MySQL数据对象.mp4
{4}–MySQL权限管理
#2.4.2#–MySQL权限管理教学案例SQL.pdf
[2.4.1]–MySQL权限管理.mp4
{5}–实践课:数据库对象
#2.5.3#–课程案例SQL.pdf
[2.5.1]–数据库对象(上).mp4
[2.5.2]–数据库对象(下).mp4
{6}–SQL语言进阶
#2.6.3#–课程涉及建表SQL(上).pdf
#2.6.4#–课程涉及建表SQL(下).pdf
[2.6.1]–SQL语言进阶(上).mp4
[2.6.2]–SQL语言进阶(下).mp4
{7}–内置函数
#2.7.2#–内置函数教学案例SQL.pdf
[2.7.1]–内置函数.mp4
{8}–触发器与存储过程
#2.8.2#–触发器与存储过程示例.pdf
[2.8.1]–触发器与存储过程.mp4
{9}–实践课:SQL进阶应用
#2.9.3#–课程案例SQL.pdf
#2.9.4#–课程用到的工具.pdf
[2.9.1]–SQL进阶(上).mp4
[2.9.2]–SQL进阶(下).mp4
{3}–Linux快速入门(赵强老师)
[3.2]–01-01-Linux简介.mp4
[3.3]–01-02-安装Linux.mp4
[3.4]–01-03-vi编辑器的使用.mp4
[3.5]–01-04-文件目录的操作.mp4
[3.6]–01-05-Linux的权限管理.mp4
[3.7]–01-06-在Linux上安装JDK.mp4
{4}–Linux复习课
{1}–第一节Linux入门
[4.1.1]–Linux入门.mp4
{2}–第二节Linux的安装
[4.2.1]–Linux的安装.mp4
{3}–第三节Linux文件与目录结构
[4.3.1]–Linux文件与目录结构.mp4
{4}–第四节Linux的VI文件编写命令
[4.4.1]–Linux的vi文件编写命令.mp4
{5}–第五节Linux网络配置和系统管理操作
[4.5.1]–查看网络IP和网关.mp4
[4.5.2]–网络IP的修改IP和IP映射.mp4
[4.5.3]–找回密码.mp4
[4.5.4]–克隆配置.mp4
{6}–第六节Linux常用基本命令
[4.6.1]–帮助命令.mp4
[4.6.2]–ls和touch及mv命令.mp4
[4.6.3]–Linux命令文件删除修改拷贝权限管理.mp4
[4.6.4]–日期类型.mp4
[4.6.5]–用户组命令.mp4
[4.6.6]–Linux查找文件命令.mp4
[4.6.7]–Linux文件压缩和解压操作命令.mp4
[4.6.8]–线程和分区方法.mp4
[4.6.9]–任务管理.mp4
{7}–第七节Linux软件包管理
[4.7.1]–Liunx软件包管理.mp4
{8}–第八节Shell编程
[4.8.1]–Shell概述.mp4
[4.8.2]–Shell的变量.mp4
[4.8.3]–Shell的传递参数.mp4
[4.8.4]–Shell的基本运算符.mp4
[4.8.5]–Shell的流程控制.mp4
[4.8.6]–Shell的常用函数.mp4
[4.8.7]–Shell的常用工具函数.mp4
{5}–Python基础复习课
{1}–开课前准备
[5.1.1]–Python下载与配置.mp4
{2}–变量和数据类型
[5.2.1]–变量.mp4
[5.2.2]–初识数据类型.mp4
{3}–数据类型
[5.3.1]–数字型.mp4
[5.3.2]–字符串.mp4
[5.3.3]–列表.mp4
[5.3.4]–元组.mp4
[5.3.5]–字典.mp4
[5.3.6]–集合.mp4
{4}–程序控制
[5.4.1]–布尔表达式.mp4
[5.4.2]–if条件判断.mp4
[5.4.3]–while循环.mp4
[5.4.4]–for循环.mp4
{5}–函数
[5.5.1]–计算机的函数概念.mp4
[5.5.2]–函数的定义和调用.mp4
{6}–类
[5.6.1]–类的概念.mp4
[5.6.2]–类的使用.mp4
[5.6.3]–self的使用.mp4
{2}–Hadoop
{10}–ZooKeeper与HA
[10.10]–1.10.9-搭建HDFS的联盟.mp4
[10.2]–1.10.1-主从架构的单点故障问题.mp4
[10.3]–1.10.2-ZooKeeper简介和体系架构.mp4
[10.4]–1.10.3-搭建ZooKeeper的Standalone模式.mp4
[10.5]–1.10.4-利用ZooKeeper实现分布式锁的秒杀.mp4
[10.6]–1.10.5-搭建ZooKeeper集群和Demo演示.mp4
[10.7]–1.10.6-Hadoop的HA架构.mp4
[10.8]–1.10.7-配置实现Hadoop的HA.mp4
[10.9]–1.10.8-什么是HDFS的联盟.mp4
{11}–HUE
[11.2]–1.11.1-HUE简介和Demo.mp4
[11.3]–1.11.2-安装所需的rpm包.mp4
[11.4]–1.11.3-配置HUE.mp4
[11.5]–1.11.4-第二阶段小节.mp4
{12}–Flume
{1}–课前准备
#12.1.1#–[下载]软件安装包.pdf
#12.1.3#–[下载]笔记&代码.pdf
{2}–Flume基本概念
[12.2.1]–12.1.1什么是Flume,为什么需要FLume.mp4
[12.2.2]–12.1.2FlumeAgent的内部原理.mp4
[12.2.3]–12.1.3Flume之间的相互通信.mp4
[12.2.4]–12.1.4Flume的环境安装.mp4
{3}–Flume的源Source
[12.3.1]–12.2.1源Source介绍.mp4
[12.3.2]–12.2.2Netcat源Source.mp4
[12.3.3]–12.2.3exec源Source.mp4
[12.3.4]–12.2.4avro源Source.mp4
{4}–Flume的Channel
[12.4.1]–12.3.1事物工作流.mp4
[12.4.2]–12.3.2内存Channel.mp4
{5}–Flume的Sink
[12.5.1]–12.4.1Sink的生命周期.mp4
[12.5.2]–12.4.2HDFSSink.mp4
[12.5.3]–12.4.3HDFSSink实战.mp4
{6}–Flume的拦截器Channel和Sink组
[12.6.1]–12.5.1拦截器.mp4
[12.6.2]–12.5.2Channel选择器.mp4
[12.6.3]–12.5.3Sink组.mp4
{7}–Flume实战案例
[12.7.1]–12.6.0实战案例介绍.mp4
[12.7.2]–12.6.1实战案例1.mp4
[12.7.3]–12.6.2实战案例2.mp4
[12.7.4]–12.6.3实战案例3.mp4
[12.7.5]–12.6.4实战案例4.mp4
[12.7.6]–12.6.5实战案例5.mp4
{14}–直播课
[14.1]–Hadoop第二阶段直播.mp4
{1}–Hadoop背景知识与起源
#1.1#–[下载]课程中的安装包.pdf
[1.3]–1.1.1-Hadoop课程概述.mp4
[1.4]–1.1.2-实验环境简介.mp4
[1.5]–1.1.3-大数据中几个基本概念.mp4
[1.6]–1.1.4-Google的基本思想.mp4
[1.7]–1.1.5-Google的论文一GFS.mp4
[1.8]–1.1.6-Google的论文二MapReduce.mp4
[1.9]–1.1.7-Google的论文三BigTable.mp4
{2}–搭建Hadoop环境
#2.8#–[下载]Hadoop环境搭建实验步骤.pdf
[2.2]–1.2.1-Hadoop的目录结构.mp4
[2.3]–1.2.2-搭建Hadoop的本地模式.mp4
[2.4]–1.2.3-搭建Hadoop的伪分布模式.mp4
[2.5]–1.2.4-免密码登录的原理和配置.mp4
[2.6]–1.2.5-搭建Hadoop的全分布模式.mp4
{3}–Hadoop的体系架构
[3.2]–1.3.1-Hadoop的体系架构概述.mp4
[3.3]–1.3.2-NameNode的职责.mp4
[3.4]–1.3.3-DataNode的职责.mp4
[3.5]–1.3.4-SecondaryNameNode的职责.mp4
[3.6]–1.3.5-Yarn的体系架构和任务调度过程.mp4
[3.7]–1.3.6-Yan的资源分配方式.mp4
[3.8]–1.3.7-HBase的体系架构简介.mp4
[3.9]–1.3.8-主从架构的单点故障问题及其解决方案.mp4
{4}–HDFS
[4.10]–1.4.9-HDFS的回收站.mp4
[4.11]–1.4.10-HDFS的配额.mp4
[4.12]–1.4.11-HDFS的快照.mp4
[4.13]–1.4.12-HDFS的安全模式和权限.mp4
[4.14]–1.4.13-HDFS集群简介.mp4
[4.15]–1.4.14-HDFS的底层原理之代理对象.mp4
[4.16]–1.4.15-使用代理对象实现数据库的连接池.mp4
[4.17]–1.4.16-什么是RPC.mp4
[4.2]–1.4.1.HDFS课程概述.mp4
[4.3]–1.4.2-通过WebConsole访问HDFS.mp4
[4.4]–1.4.3-通过命令行操作HDFS.mp4
[4.5]–1.4.4-使用JavaAPI创建HDFS目录和HDFS的权限.mp4
[4.6]–1.4.5-使用JavaAPI上传和下载数据.mp4
[4.7]–1.4.6-使用JavaAPI获取HDFS的元信息.mp4
[4.8]–1.4.7-HDFS数据上传的过程和原理.mp4
[4.9]–1.4.8-HDFS数据下载的过程和原理.mp4
{5}–MapReduce
#5.28#–[直播笔记]第一阶段小结.pdf
[5.10]–1.5.9-字符串的排序.mp4
[5.11]–1.5.10-对象的排序.mp4
[5.12]–1.5.11-什么是分区.mp4
[5.13]–1.5.12-分区的案例-根据部门号建立分区.mp4
[5.14]–1.5.13-什么是Combiner.mp4
[5.15]–1.5.14-什么是Shuffle.mp4
[5.16]–1.5.15-数据去重.mp4
[5.17]–1.5.16-关系型数据库中的多表查询.mp4
[5.18]–1.5.17-分析等值连接的数据处理过程.mp4
[5.19]–1.5.18-实现等值连接的MapReduce程序.mp4
[5.20]–1.5.19-分析自连接的数据处理过程.mp4
[5.21]–1.5.20-实现MapReduce的自连接.mp4
[5.22]–1.5.21-分析倒排所有的数据处理流程.mp4
[5.23]–1.5.22-实现倒排索引的MapReduce程序.mp4
[5.24]–1.5.23-使用MRUnit进行单元测试.mp4
[5.25]–1.5.24-第一个阶段小结.mp4
[5.27]–[直播8月30日]Hadoop第一阶段.mp4
[5.2]–1.5.1-MapReduce课程概述.mp4
[5.3]–1.5.2-分析WordCount数据处理的过程.mp4
[5.4]–1.5.3-开发自己的WordCount程序.mp4
[5.5]–1.5.4-分析求每个部门工资总额的数据处理流程.mp4
[5.6]–1.5.5-开发MapReduce求每个部门的工资总额.mp4
[5.7]–1.5.6-Hadoop的序列化机制.mp4
[5.8]–1.5.7-序列化案例求每个部门的工资总额.mp4
[5.9]–1.5.8-数字的排序.mp4
{6}–Hbase
#6.9#–[补充]hamcrest-core-1.3.jar.pdf
[6.10]–1.6.8-HBase数据保存的过程和Region的分裂.mp4
[6.11]–1.6.9-HBase的过滤器.mp4
[6.12]–1.6.10-HBase上的MapReduce.mp4
[6.2]–1.6.1-NoSQL数据库简介.mp4
[6.3]–1.6.2-HBase的体系架构和表结构.mp4
[6.4]–1.6.3-搭建HBase的本地模式和伪分布模式.mp4
[6.5]–1.6.4-搭建HBase的全分布环境和HA.mp4
[6.6]–1.6.5-HBase在ZooKeeper中保存的数据和HA演示.mp4
[6.7]–1.6.6-通过命令行操作HBase.mp4
[6.8]–1.6.7-使用Java操作HBase.mp4
{7}–Hive
[7.10]–1.7.9-Hive的查询.mp4
[7.11]–1.7.10-Hive的Java客户端.mp4
[7.12]–1.7.11-Hive的自定义函数.mp4
[7.2]–1.7.1-数据分析引擎和Hive简介.mp4
[7.3]–1.7.2-Hive的体系架构.mp4
[7.4]–1.7.3-搭建Hive的嵌入模式.mp4
[7.5]–1.7.4-搭建Hive的本地模式和远程模式.mp4
[7.6]–1.7.5-Hive的内部表.mp4
[7.7]–1.7.6-Hive的分区表.mp4
[7.8]–1.7.7-Hive的外部表.mp4
[7.9]–1.7.8-Hive的桶表和视图.mp4
{8}–Pig
[8.2]–1.8.1-Pig简介和安装配置.mp4
[8.3]–1.8.2-Pig的常用命令.mp4
[8.4]–1.8.3-Pig的数据模型.mp4
[8.5]–1.8.4-使用PigLatin语句处理数据.mp4
[8.6]–1.8.5-Pig的自定义运算函数和自定义过滤函数.mp4
[8.7]–1.8.6-Pig的自定义加载函数.mp4
{9}–Sqoop
[9.2]–1.9.1-数据采集引擎和准备实验环境.mp4
[9.3]–1.9.2-Sqoop的原理和安装配置.mp4
[9.4]–1.9.3-使用Sqoop采集数据.mp4
{3}–NoSQL数据库
{1}–Redis
#1.13#–[下载]部署RedisCluster.pdf
[1.10]–2.1.9-Redis主从复制.mp4
[1.11]–2.1.10.Redis的分片.mp4
[1.12]–2.1.11-Redis的HA哨兵机制.mp4
[1.14]–2.1.12-RedisCluster.mp4
[1.2]–2.1.1-Redis简介.mp4
[1.3]–2.1.2-Redis的安装配置和基本操作.mp4
[1.4]–2.1.3-Redis数据类型和案例分析.mp4
[1.5]–2.1.4-Redis的事务.mp4
[1.6]–2.1.5-Redis的锁机制.mp4
[1.7]–2.1.6-Redis的消息机制.mp4
[1.8]–2.1.7-RDB的持久化.mp4
[1.9]–2.1.8-AOF的持久化.mp4
{2}–MongoDB
[2.10]–3.1.9-MongoDB的批处理.mp4
[2.2]–3.1.1-MongoDB简介.mp4
[2.3]–3.1.2-MongoDB的安装和配置.mp4
[2.4]–3.1.3-MongoDB的体系架构.mp4
[2.5]–3.1.4-使用MongoShell.mp4
[2.6]–3.1.5-使用MongoShell的启动配置文件.mp4
[2.7]–3.1.6-MongoShell的基本操作和数据类型.mp4
[2.8]–3.1.7-使用MongoDB的Web控制台.mp4
[2.9]–3.1.8-MongoDB的CRUD操作.mp4
{4}–Kafka
{10}–Kafka的架构注册表和Ksql
[10.1]–3.9.1.1Java的Avro(一).mp4
[10.2]–3.9.1.2Java的Avro(二).mp4
[10.3]–3.9.1.3Java的Avro(三).mp4
[10.4]–3.9.2.1Kafka注册表(一).mp4
[10.5]–3.9.2.2Kafka注册表(二).mp4
[10.6]–3.9.2.3Kafka注册表(三).mp4
[10.7]–3.9.2.4Kafka注册表(四).mp4
[10.8]–3.9.3Ksql.mp4
{11}–Kafka的运维管理
[11.1]–3.10.1Kafka的安全性.mp4
[11.2]–3.10.2.1Kafka的集群和容灾(一).mp4
[11.3]–3.10.2.2Kafka的集群和容灾(二).mp4
[11.4]–3.10.3Kafka的监控.mp4
{2}–Kafka理论
[2.1]–3.1.1什么是Kafka.mp4
[2.2]–3.1.2Kafka的Topic.mp4
[2.3]–3.1.3Kafka的Brokers.mp4
[2.4]–3.1.4Kafka的主题复制.mp4
{3}–Kafka环境安装
[3.1]–3.2.1安装Kafka(Ubuntu).mp4
[3.2]–3.2.2安装kafka(Centos).mp4
[3.3]–3.2.3安装kafka(Windows).mp4
[3.4]–3.2.4安装kafka(Confluent).mp4
{4}–Kafka的生产者消费者
[4.1]–3.3.1Kafka的生产者命令.mp4
[4.2]–3.3.2Kafka的消费key.mp4
[4.3]–3.3.3Kafka的消费者.mp4
[4.4]–3.3.4Broker发现和zk.mp4
{5}–Kafka的命令行使用
[5.1]–3.4.1Topic相关.mp4
[5.2]–3.4.2生产者相关.mp4
[5.3]–3.4.3消费者相关.mp4
[5.4]–3.4.4offset部分.mp4
[5.5]–3.4.5图形UI.mp4
{6}–Kafka的生产者开发API
[6.1]–3.5.1Kafka开发环境准备.mp4
[6.2]–3.5.2生产者模型.mp4
[6.3]–3.5.3生产者的序列化.mp4
[6.4]–3.5.4生产者的自定义分区.mp4
{7}–Kafka的消费者API
[7.10]–3.6.3.2组协调器和反序列化(二).mp4
[7.11]–3.6.3.3组协调器和反序列化(三).mp4
[7.12]–3.6.3.4组协调器和反序列化(四).mp4
[7.1]–3.6.1.1JavaAPI介绍(一).mp4
[7.2]–3.6.1.2JavaAPI介绍(二).mp4
[7.3]–3.6.1.3JavaAPI介绍(三).mp4
[7.4]–3.6.1.4JavaAPI介绍(四).mp4
[7.5]–3.6.2.1API同步异步接收(一).mp4
[7.6]–3.6.2.2-3API同步异步接收(二、三).mp4
[7.7]–3.6.2.4API同步异步接收(四).mp4
[7.8]–3.6.2.5API同步异步接收(五).mp4
[7.9]–3.6.3.1组协调器和反序列化(一).mp4
{8}–Kafka的连接器
[8.1]–3.7.1Kafka的Connect功能.mp4
[8.2]–3.7.2.1Kafka的Connect使用(一).mp4
[8.3]–3.7.2.2Kafka的Connect使用(二).mp4
[8.4]–3.7.2.3Kafka的Connect使用(三).mp4
{9}–Kafka的流处理
[9.10]–3.8.4.4流编程实战下(四).mp4
[9.11]–3.8.4.5流编程实战下(五).mp4
[9.12]–3.8.4.6流编程实战下(六).mp4
[9.1]–3.8.1Kafka的流基本组件.mp4
[9.2]–3.8.2流操作.mp4
[9.3]–3.8.3.1流编程实战上(一).mp4
[9.4]–3.8.3.2流编程实战上(二).mp4
[9.5]–3.8.3.3流编程实战上(三).mp4
[9.6]–3.8.3.4流编程实战上(四).mp4
[9.7]–3.8.4.1流编程实战下(一).mp4
[9.8]–3.8.4.2流编程实战下(二).mp4
[9.9]–3.8.4.3流编程实战下(三).mp4
{5}–Scala
{10}–scala函数式编程
#10.1#–随堂源代码下载.pdf
[10.2]–2.10.1scala函数式编程-01模式匹配.mp4
[10.3]–2.10.2scala函数式编程-02样例类.mp4
[10.4]–2.10.3scala函数式编程-03匿名函数.mp4
[10.5]–2.10.4scala函数式编程-04带函数参数和闭包.mp4
[10.6]–2.10.5scala函数式编程-05return表达式.mp4
[10.7]–2.10.6scala函数式编程-06偏函数.mp4
[10.8]–2.10.7scala函数式编程-07柯里化.mp4
[10.9]–2.10.8scala函数式编程-08高阶函数.mp4
{11}–类型参数
#11.1#–随堂源代码下载.pdf
[11.2]–2.11.1类型参数-01泛型类.mp4
[11.3]–2.11.2类型参数-02泛型函数.mp4
[11.4]–2.11.3类型参数-03类型边界.mp4
[11.5]–2.11.4类型参数-04视图界定.mp4
{12}–scala设计模式
#12.1#–随堂源代码下载.pdf
[12.2]–2.12.1scala设计模式-01创建型.mp4
[12.3]–2.12.2scala设计模式-02结构型.mp4
[12.4]–2.12.3scala设计模式-03行为型-值对象和空对象.mp4
[12.5]–2.12.4scala设计模式-04行为型-策略和责任链等.mp4
{1}–scala概述
#1.1#–Scala语言基础PDF下载.pdf
#1.3#–随堂源代码下载.pdf
[1.2]–Scala开发环境准备.pdf
[1.4]–2.1.1scala概述-01Scala概述.mp4
[1.5]–2.1.2scala概述-02开发环境.mp4
[1.6]–2.1.3scala概述-03包的引入和定义.mp4
{2}–scala基础语法
#2.1#–随堂源代码下载.pdf
[2.2]–2.2.1scala基础语法-01变量与常量.mp4
[2.3]–2.2.2scala基础语法-02常用数据类型.mp4
[2.4]–2.2.3scala基础语法-03字符串常用操作.mp4
[2.5]–2.2.4scala基础语法-04正则表达式.mp4
[2.6]–2.2.5scala基础语法-05文件读写.mp4
{3}–scala运算符
#3.1#–随堂源代码下载.pdf
[3.2]–2.3.1scala运算符.mp4
{4}–Scala程序控制结构
#4.1#–随堂源代码下载.pdf
[4.2]–2.4.1Scala程序控制结构.mp4
{5}–Scala函数
#5.1#–随堂源代码下载.pdf
[5.2]–2.5.1Scala函数.mp4
{6}–面向对象(基础)
#6.6#–随堂源代码下载.pdf
[6.1]–2.6.1面向对象(基础)-01类和对象.mp4
[6.2]–2.6.2面向对象(基础)-02构造器.mp4
[6.3]–2.6.3面向对象(基础)-03继承.mp4
[6.4]–2.6.4面向对象(基础)-04匿名子类.mp4
[6.5]–2.6.5面向对象(基础)-05抽象.mp4
{7}–面向对象(高级)
#7.3#–随堂源代码下载.pdf
[7.1]–2.7.1面向对象(高级)-01特质.mp4
[7.2]–2.7.2面向对象(高级)-02隐式转换.mp4
{8}–数据结构(基础)
#8.5#–随堂源代码下载.pdf
[8.1]–2.8.1数据结构(基础)-01数组.mp4
[8.2]–2.8.2数据结构(基础)-02元组.mp4
[8.3]–2.8.3数据结构(基础)-03列表.mp4
[8.4]–2.8.4数据结构(基础)-04集合.mp4
{9}–数据结构(高级)
#9.1#–随堂源代码下载.pdf
[9.2]–2.9.1数据结构(高级)-01映射.mp4
[9.3]–2.9.2数据结构(高级)-02拉链操作.mp4
[9.4]–2.9.3数据结构(高级)-03迭代器.mp4
[9.5]–2.9.4数据结构(高级)-04并行集合.mp4
{6}–Spark
{2}–Spark基本概念
[2.1]–4.1.1Spark起源和功能介绍.mp4
[2.2]–4.1.2Spark环境的准备和软件下载.mp4
[2.3]–4.1.3Ubuntu环境下的安装.mp4
[2.4]–4.1.4CentOS环境下的安装.mp4
[2.5]–4.1.5Windows环境下的安装.mp4
[2.6]–4.1.6IntelliJ环境下Scala程序运行Spark.mp4
[2.7]–4.1.7搭建PySpark的开发环境.mp4
[2.8]–4.1.8云环境的使用.mp4
{3}–基本RDD
[3.1]–4.2.1rdd的介绍.mp4
[3.2]–4.2.2rdd实战课程.mp4
[3.3]–4.2.3Flatmap案例使用.mp4
[3.4]–4.2.4集合操作.mp4
[3.5]–4.2.5Action如何使用.mp4
[3.6]–4.2.6cache和分区功能.mp4
{4}–PairRDD
[4.10]–4.3.10广播变量.mp4
[4.11]–4.3.11累加器.mp4
[4.1]–4.3.1PairRdd的map和filter.mp4
[4.2]–4.3.2reducebykey和groupbykey.mp4
[4.3]–4.3.3keyby和countbykey.mp4
[4.4]–4.3.4combinebykey.mp4
[4.5]–4.3.5aggregatebykey.mp4
[4.6]–4.3.6foldbykey.mp4
[4.7]–4.3.7sortbykey.mp4
[4.8]–4.3.8join.mp4
[4.9]–4.3.9partition.mp4
{5}–Dataframe基础
[5.1]–4.4.1什么是Spark的Dataframe.mp4
[5.2]–4.4.2什么是Dataframe的数据类型.mp4
{6}–Dataframe进阶
[6.1]–4.5.1什么是SparkDF的聚合和连接.mp4
[6.2]–4.5.2什么是SparkDF的链接.mp4
{7}–SparkSQL
[7.1]–4.6.1什么是SparkSQL.mp4
[7.2]–4.6.2什么是Spark的数据源.mp4
{8}–Spark集群管理
[8.1]–4.7.1Spark大数据集群环境准备.mp4
[8.2]–4.7.2spark-submit使用.mp4
[8.3]–4.7.3sparkonyarn使用.mp4
[8.4]–4.7.4spark性能调优和监控.mp4
{9}–Spark流处理
[9.1]–4.8.1sparkstream介绍.mp4
[9.2]–4.8.2DStreamAPI使用.mp4
[9.3]–4.8.3StructureStream的使用.mp4
[9.4]–4.8.4Spark流和Kafka联动.mp4
[9.5]–4.8.5流处理的时间窗口.mp4
{7}–Storm
{2}–Storm基础
[2.1]–5.1.1-大数据实时计算框架简介.mp4
[2.2]–5.1.2-Storm的体系架构.mp4
[2.3]–5.1.3-Storm的伪分布模式的搭建.mp4
[2.4]–5.1.4-Storm的全分布模式和HA.mp4
[2.5]–5.1.5-Storm的Demo演示-单词计数.mp4
[2.6]–5.1.6-Storm在ZooKeeper中保存的数据.mp4
{3}–Storm应用开发
[3.1]–5.2.1-WordCount数据流动的过程.mp4
[3.2]–5.2.2-开发自己的Storm的WordCount程序.mp4
[3.3]–5.2.3-部署和运行Storm任务.mp4
[3.4]–5.2.4-Storm任务执行的过程.mp4
[3.5]–5.2.5-Storm内部通信的机制.mp4
{4}–集成Storm
[4.1]–5.3.1-典型的实时计算系统的架构.mp4
[4.2]–5.3.2-集成Storm与Redis.mp4
[4.3]–5.3.3-集成Storm与HDFS.mp4
[4.4]–5.3.4-集成Storm与HBase.mp4
{8}–Flink
{2}–Flink基础
[2.10]–6.1.10-对比各种流式计算引擎.mp4
[2.1]–6.1.1-Flink的简介.mp4
[2.2]–6.1.2-Flink的体系架构.mp4
[2.3]–6.1.3-部署Flink的Standalone的模式.mp4
[2.4]–6.1.4-Flink-On-Yarn的两种模式.mp4
[2.5]–6.1.5-Flink-on-Yarn的两种模式的区别.mp4
[2.6]–6.1.6-Flink-On-Yarn的内部实现.mp4
[2.7]–6.1.7-Flink的HA.mp4
[2.8]–6.1.8-FlinkUI界面介绍.mp4
[2.9]–6.1.9-Flink的分布式缓存.mp4
{3}–Flink入门开发案例
[3.1]–6.2.1-Flink批处开发.mp4
[3.2]–6.2.2-Flink流处理开发.mp4
[3.3]–6.2.3-使用Flink-Scala-Shell.mp4
[3.4]–6.2.4-Flink的并行度分析.mp4
{4}–Flink的DataSetAPI
[4.1]–6.3.1-map和flatMap和mAPPartition.mp4
[4.2]–6.3.2-filter与distinct.mp4
[4.3]–6.3.3-Join操作.mp4
[4.4]–6.3.4-笛卡尔积.mp4
[4.5]–6.3.5-First-N分析.mp4
[4.6]–6.3.6-外连接操作.mp4
{5}–Flink的DataStreamAPI
[5.1]–6.4.1-基本的数据源示例.mp4
[5.2]–6.4.2-自定义数据源.mp4
[5.3]–6.4.3-内置的Connector.mp4
[5.4]–6.4.4-DataStream的转换操作.mp4
[5.5]–6.4.5-DataSink.mp4
{6}–Flink高级特性
[6.1]–6.5.1-广播变量.mp4
[6.2]–6.5.2-累加器和计数器.mp4
{7}–状态管理和恢复
[7.1]–6.6.1-状态State.mp4
[7.2]–6.6.2-检查点的配置.mp4
[7.3]–6.6.3-State的后端存储模式.mp4
[7.4]–6.6.4-修改StateBackend的两种方式.mp4
[7.5]–6.6.5-重启策略.mp4
{8}–FlinkTable&SQL
[8.1]–6.7.1-Flink的Table和SQL简介.mp4
[8.2]–6.7.2-使用TableAPI.mp4
[8.3]–6.7.3-使用FlinkSQL.mp4
[8.4]–6.7.4-使用FlinkSQLClient.mp4
{9}–网易有道项目案例
{1}–平台介绍
[1.2]–1.1.1-平台介绍.mp4
{2}–系统架构和设计
[2.1]–1.2.1-平台架构.mp4
[2.2]–1.2.2-日志原始数据输入.mp4
[2.3]–1.2.3-业务数据输入.mp4
[2.4]–1.2.4-日志数据源生成.mp4
[2.5]–1.2.5-日志数据源存储到预聚合数据库Druid.mp4
[2.6]–1.2.6-日志数据源存储到Hive数据库.mp4
[2.7]–1.2.7-基本KPI指标的计算.mp4
[2.8]–1.2.8-数仓任务调度系统.mp4
[2.9]–1.2.9-数据展示.mp4
{3}–案例
#3.1#–[资料下载]作业百度链接地址.pdf
[3.2]–1.3.1-NPS报告.mp4
[3.3]–1.3.2-渠道留存报告.mp4
课件
09、网易有道项目案例
09、网易有道项目案例
有道离线日志课件.zip
NPS作业
nps_data_sort.zip
数据导出指导.txt
数据装入指导.txt
渠道留存率作业
remain_data.zip
数据导出指导.txt
数据装入指导.txt
1-8 课件
01、零基础复习课
课件与课堂笔记.zip
02、Hadoop
1.1-Hadoop背景知识与起源.zip
1.10-ZooKeeper与HA.zip
1.11.1-大数据集成管理工具HUE.pdf
1.12flume代码笔记.zip
1.12课件PPT.zip
1.2-搭建Hadoop环境.zip
1.3-Hadoop的体系架构.zip
1.4-HDFS.zip
1.5-MapReduce.zip
1.6-HBase.zip
1.7-Hive.zip
1.8-Pig.zip
1.9-Sqoop.zip
搭建Hadoop环境.docx
第一阶段Hadoop.zip
00、软件和安装包
flink.tar
rhel-server-7.4-x86_64-dvd.iso
tree命令.zip
Flink
flink-1.7.2-bin-hadoop27-scala_2.11.tgz
Hadoop生态圈组件
apache-flume-1.7.0-bin.tar.gz
apache-hive-2.2.0-src.tar.gz
apache-hive-2.3.0-bin.tar.gz
apache-storm-1.0.3.tar.gz
hadoop-2.4.1.zip
hadoop-2.7.3.tar.gz
hadoop-native-64-2.7.0.tar
hbase-1.3.1-bin.tar.gz
hue-4.0.1.tgz
jdk-8u181-linux-x64.tar.gz
MRUnit.zip
pig-0.17.0.tar.gz
sqoop-1.4.5.bin__hadoop-0.23.tar.gz
ZooInspector.zip
zookeeper-3.4.10.tar.gz
从这里下载MRUnit.pptx
MRUnit
apache-mrunit-1.1.0-hadoop1-bin.tar.gz
mrunit-1.1.0-hadoop2.jar
MongoDB课程实验环境
emp.csv
mongodb-linux-x86_64-enterprise-rhel70-3.4.10.tgz
Percona-XtraDB-Cluster-shared-55-5.5.37-25.10.756.el6.x86_64.rpm.zip
数据脚本.txt
MySQL
mysql-5.7.19-1.el7.x86_64.rpm-bundle.tar
mysql-connector-java-5.1.43-bin.jar
MySQL_Front_Setup.1765185107.exe
OracleXP实验环境
10201_database_win32.zip
Windows XP Professional.vmdk
Redis
jedis-2.1.0.jar.zip
nutcracker-0.3.0.tar.gz
redis-3.0.5.tar.gz
集成redis的jar包.zip
MemCached
libevent-2.0.21-stable.tar.gz
memcached-1.2.8-repcached-2.2.tar.gz
memcached-1.4.25.tar.gz
spymemcached-2.10.3.jar
集成redis的jar包
commons-pool2-2.3.jar
jedis-2.7.0.jar
storm-redis-1.0.3.jar
1.12Flume
apache-flume-1.9.0-bin.tar.gz
hadoop-2.9.2.tar.gz
hbase-1.4.9-bin.tar.gz
jdk-8u144-windows-x64.exe
jdk-8u161-linux-x64.tar.gz
ubuntu-16.04.5-server-amd64.iso
03、NoSQL数据库
2.1-Redis.zip
3.1-MongoDB.zip
redis cluster部署.docx
04、Kafka
课堂笔记及代码.zip
Kafka
confluent-5.4.0-2.12.tar.gz
confluent_latest_linux_amd64.tar.gz
grafana-6.6.2.linux-amd64.tar.gz
jdk-8u144-windows-x64.exe
jdk-8u161-linux-x64.tar(1).gz
jdk-8u161-linux-x64.tar.gz
jmx_prometheus_javaagent-0.12.0.jar
kafka-2_0_0.yml
kafkatool_64bit.exe
kafka_2.12-2.3.0.tgz
kse-543-setup.exe
prometheus-2.16.0.linux-amd64.tar.gz
ubuntu-16.04.5-server-amd64.iso
05、Scala
01-code-live.zip
02-code-live.zip
03-code-live.zip
04-code-live.zip
05-code-live.zip
06-code-live.zip
07-code-live.zip
08-code-live.zip
09-code-live.zip
10-code-live.zip
11-code-live.zip
12-code-live.zip
ppt.zip
06、Spark
Spark PPT.zip
启动集群.txt
spark-2.4.5-bin-hadoop2.7
linux下spark安装步骤.txt
spark-2.4.5-bin-hadoop2.7.tgz
启动集群.txt
Spark课堂代码
exec01_java_scala.zip
exec_python.zip
课程准备资料
Anaconda3-2018.12-Linux-x86_64.sh
Anaconda3-2019.07-Windows-x86_64.exe
confluent-5.4.0-2.12.tar.gz
confluent_latest_linux_amd64.tar.gz
eclipse-inst-win64.exe
hadoop-2.9.2.tar.gz
ideaIC-2019.3.3.exe
jdk-8u144-windows-x64.exe
jdk-8u161-linux-x64.tar.gz
kafka-ubuntu-整合环境.txt
linux下spark安装步骤.txt
pycharm-community-anaconda-2019.2.3.exe
spark-2.4.3-bin-hadoop2.7.tgz
spark-2.4.5-bin-hadoop2.7.tgz
ubuntu-16.04.5-server-amd64.iso
VMware-workstation-full-15.5.0-14665864.exe
windows下的安装步骤.txt
启动集群.txt
winutils
bin
winutils.exe
07、Storm
实时计算引擎Storm.zip
08、Flink
6Flink.zip
10、网易严选项目实战
001 电商严选数据仓库实战.zip
002 电商严选实时数仓实战.zip
002 电商严选实时数仓实战代码.zip
[数据]电商严选数据仓库实战.rar
代码.zip
11、网易有道项目实战
course-showcase.zip
有道广告离线数据处理实战.zip
有道广告精准投放推荐系统.zip
网易有道广告实时数据处理实战.zip
有道广告
广告离线和实时处理
impr-click.tar.gz
impr
00.tar.gz
01.tar.gz
02.tar.gz
03.tar.gz
04.tar.gz
05.tar.gz
06.tar.gz
07.tar.gz
08.tar.gz
09.tar.gz
10.tar.gz
11.tar.gz
12.tar(1).gz
12.tar.gz
13.tar.gz
14.tar.gz
15.tar.gz
16.tar.gz
17.tar.gz
18.tar.gz
19.tar.gz
20.tar.gz
21.tar(1).gz
21.tar.gz
22.tar.gz
23.tar.gz
精准广告
app_categories.tar.gz
gender_label.tar.gz
app_install_seq
part-00000-b43f45b4-92ff-4a3e-9922-6afa140e99c3-c000.json.tar.gz
part-00001-b43f45b4-92ff-4a3e-9922-6afa140e99c3-c000.json.tar.gz
part-00002-b43f45b4-92ff-4a3e-9922-6afa140e99c3-c000.json.tar.gz
part-00003-b43f45b4-92ff-4a3e-9922-6afa140e99c3-c000.json.tar.gz
part-00004-b43f45b4-92ff-4a3e-9922-6afa140e99c3-c000.json.tar.gz
part-00005-b43f45b4-92ff-4a3e-9922-6afa140e99c3-c000.json.tar.gz
part-00006-b43f45b4-92ff-4a3e-9922-6afa140e99c3-c000.json.tar.gz
part-00007-b43f45b4-92ff-4a3e-9922-6afa140e99c3-c000.json.tar.gz
part-00008-b43f45b4-92ff-4a3e-9922-6afa140e99c3-c000.json.tar.gz
part-00009-b43f45b4-92ff-4a3e-9922-6afa140e99c3-c000.json.tar.gz
_SUCCESS.tar.gz
user_ad_click
part-0000-0009.tar.gz
part-0010-0019.tar.gz
part-0020-0029.tar.gz
part-0030-0039.tar.gz
part-0040-0049.tar.gz
user_installed_app
part-00000-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00001-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00002-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00003-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00004-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00005-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00006-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00007-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00008-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00009-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00010-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00011-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00012-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00013-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00014-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00015-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00016-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00017-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00018-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
part-00019-b9286bcd-7d71-46f2-b517-03528b743ec0-c000.tar.gz
12、网易游戏项目实战
1-2图存储代码及资料.zip
3-4图深度学习代码.zip
course-showcase.zip
kudu-demo-master.zip
presto-demo-master.zip
图计算PPT.zip
多数据源游戏业务实时分析 (1).zip
多数据源游戏业务实时分析.zip
实时数据处理实战课件.zip
有道广告离线数据处理实战.zip
有道广告精准投放推荐系统.zip
网易有道广告实时数据处理实战.zip
002实时数据处理实战
2.1数据-代码
flink-gamelog-etl-no-homeworkanswer.zip
flink-gamelog-etl-with-homeworkanswer.zip
merged.gz
2.2代码
flink-logmonitor-with-hw-answer.zip
flink-logmonitor-without-hw-answer.zip
实验环境
flinkcourse-debian8.11_gnome_cdh5.15.1.ova
003多数据源游戏业务分析
cdh-lyb-5.13.0.zip
presto-server-0.225.tar.gz
13、网易云音乐项目实战
003 推荐算法应用.zip
UserAction.zip
每日推歌实战.zip
网易云音乐搜索业务实时特征实战.zip
001图计算
1-2图储存部分实验环境.zip
3-4图深度学习实验环境.zip


