
教程帖-爬取网易云课堂上所有python课程的基本信息
丁可乐可口
自学统计学,擅长可靠性分析

3 人赞同了该文章
这是我的第一篇关于python爬虫文章,在这个专栏里,我记录的是我在爬取网页中所碰到的问题,所以有一些很基础的东西,我不会说,所以这个专栏比较适合有一点爬虫基础的人。
目前,python越来越炙手可热,因此许多人开始将学习python。为此,我们想了解一下,著名“充电”网站-网易云课堂上关于python课程的信息,我们在搜索页面上,输入python,可以发现,有大量的关于python课程,看来,python真的非常热门。
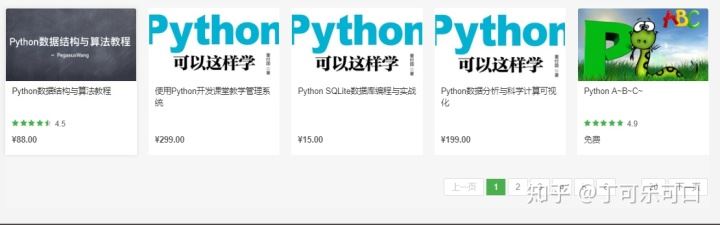
我们要爬取的信息包括课程名,课时数,价格,学习人数以及评分。
在滚动鼠标往下查看的时候,课程的信息会跟着出现,初步推断该网页使用Ajax(异步加载)的方式来呈现网页的。我们右击,选择最底下的检查(快捷键F12,笔记本为Fn+F12)。选择Network- XHR,刷新一下。
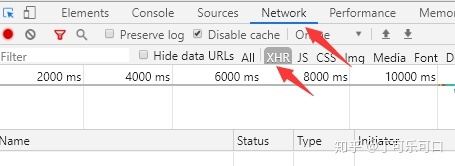
可以看到有一个studycourse.json的json文件,单击一下,在右侧的Preview中可以看到显示的课程信息。
点开list前面的小三角,课程的相关信息都在里面。好了我们大致知道怎么爬取这些信息了。数据全在一个json文件里,然后用jsonpath库中的jsonpath方法,就可以得到每个键下的值
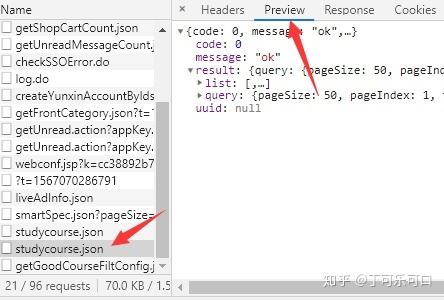
这时候,我们在点击Preview旁边的Headers,这里可以看到一些网页的信息。在General中,可以看到,该json数据需要通过post方法得到。
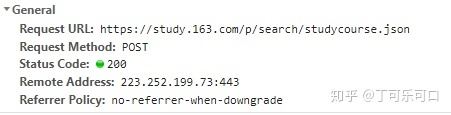
既然方法是post,那必须要传递参数上去,在Headers中的我们注意到最后一部分有一个Request Payload
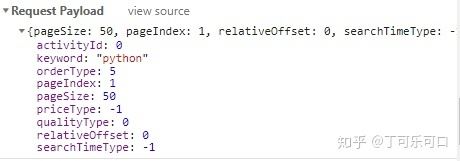
一般我们post上去的是一个字典,而Requests Payload是什么东西?
百度了一下,Requests Payload要求传一个json文件,所以我们需要把字典格式转成一个json格式文件。
因此解析网页,得到的json数据的函数如下
def post_html(pageNumber): # 解析网页 url = "http://job.nju.edu.cn/recruitmentFair/loadMoreFair" header = { "Accept": "aapplication/json, text/plain, */*", "Host": "job.nju.edu.cn", "Origin": "http://job.nju.edu.cn", "Content-Type": "application/x-www-form-urlencoded;charset=UTF-8", "Referer": "http://job.nju.edu.cn/", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36" } # post上去的信息 data = { "pageNumber": 0, "pageSize": 15 } # 实现翻页 data["pageNumber"] = pageNumber try: response = requests.post(url, data=json.dumps(data),headers=header) # json.dumps(data)是将字典格式转为json格式 response.raise_for_status return response.json except: return
其中requests.post函数中的data=json.dumps(data)这句,就是将字典格式的data转变为json格式,另外,注意到,Requests Payloa中的pageNumber值对应的是页数.
然后我们在网页检查中的json文件里,找到我们需要的信息,因此我们的解析json文件得到信息的函数如下:
def save_info(info): price = # 存储课程的价格 productName = jsonpath.jsonpath(info,'$..productName') # 课程名称 lessonCount = jsonpath.jsonpath(info,'$..lessonCount') # 课程节数 originalPrice = jsonpath.jsonpath(info,'$..originalPrice') # 课程原价 discountPrice = jsonpath.jsonpath(info,'$..discountPrice') # 课程折扣价 learnerCount = jsonpath.jsonpath(info,'$..learnerCount') # 学习人数 score = jsonpath.jsonpath(info, '$..score') # 课程评分
这里有个细节问题,我们是以折扣价作为网易云课堂上课程信的价格,但对于没有打折的课,这个值是Null,因此我们需要if-else来判断有没打折,逻辑是:
如果折扣价的值为None,那么就是原价,否则就为折扣价。
for num,val in enumerate(discountPrice): if val is None: # 不打折,价格就是原价 price.append(originalPrice[num]) else: price.append(val)
然后在这个函数中,将得到的数据写入到一个csv文件中
with open("网易公开课所有python课程信息.csv","a",newline='') as f: f_csv = csv.writer(f) for i in range(0,len(productName)): f_csv.writerow([productName[i],lessonCount[i],price[i],learnerCount[i],score[i]])
说明一下,这里就是遍历所有列表元素,一一取出来,这里有点啰嗦,其实可以利用zip函数将所有列表合并为一个大列表,利用csv库中writerows函数来写,这样会简单一点。
info = list(zip(productName,lessonCount,price,learnerCount,score))with open("网易公开课所有python课程信息.csv","a",newline='') as f: f_csv = csv.writer(f)

